
Geek
Inteligencia artificial: entre el progreso y la cautela


Geek
Puebla se convierte en el epicentro del gaming en Latinoamérica con la inauguración del S-Factor X3

Este fin de semana, la ciudad de Puebla se consolida como un referente internacional de la tecnología y el entretenimiento digital con el arranque del S-Factor X3. El evento, celebrado en el Centro Expositor los días 18 y 19 de julio, es considerado el festival gratuito de videojuegos, esports y cultura pop más grande de México y un referente clave en América Latina.

La ceremonia inaugural estuvo encabezada por el gobernador del estado, Alejandro Armenta, marcando el inicio de dos jornadas de intensa competencia y convivencia para las juventudes y familias poblanas.Cifras récord y alcance globalEl festival estima una afluencia superior a los 25 mil asistentes a lo largo del fin de semana. En el ámbito competitivo, el S-Factor X3 congrega a más de 2 mil 500 jugadores profesionales y entusiastas de 24 países, quienes se disputarán los primeros lugares en torneos internacionales clasificatorios de títulos icónicos como Super Smash Bros. Ultimate, Street Fighter 6 y Mortal Kombat 1.
La magnitud de la organización corre a cargo de MainGame GG, empresa que logró la alianza de gigantes mundiales de la industria como Sony, PlayStation, Tencent y SNK, garantizando la calidad tecnológica de los torneos. Más allá de las pantallas: Cultura Pop y Compromiso SocialEl evento no se limita a las consolas. La cartelera se complementa con un nutrido programa que incluye:Concursos internacionales de cosplay. Paneles con reconocidos actores de doblaje de la cultura geek.Espectáculos musicales y experiencias inmersivas gratuitas.Adicionalmente, los organizadores destacaron la faceta solidaria del encuentro mediante una alianza estratégica de responsabilidad social con la organización Save the Children, con el objetivo de promover acciones en favor del bienestar infantil dentro del marco del festival. Con el desarrollo del S-Factor X3, Puebla busca no solo detonar el turismo local durante el fin de semana, sino proyectar al estado como un polo de innovación, creatividad y desarrollo para las nuevas generaciones en la era digital.Para conocer más detalles visuales sobre los invitados y la cartelera completa del evento, puedes revisar este Avance del S Factor X3. Este video corto detalla de forma rápida las expectativas de asistencia, invitados especiales y las dinámicas gratuitas dentro del Centro Expositor de Puebla.
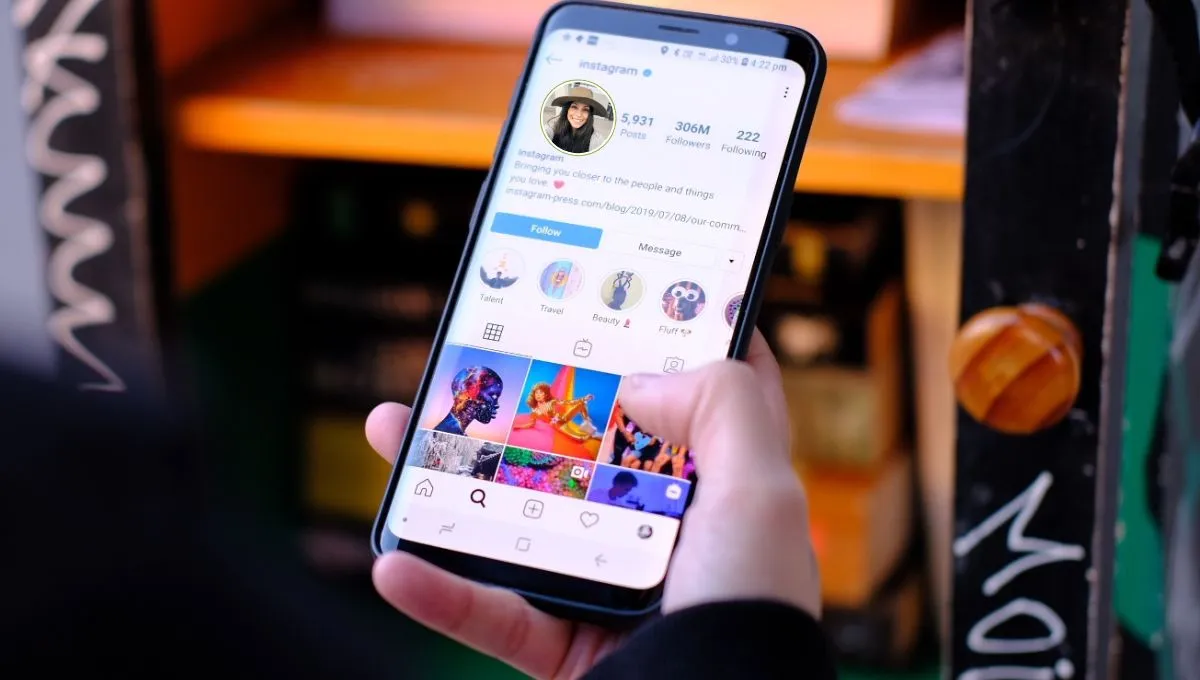

La reciente integración de esta herramienta de inteligencia artificial ha encendido las alarmas sobre la privacidad, permitiendo que las imágenes de perfiles públicos sean usadas como referencia para creaciones digitales sin consentimiento.
Por: Redacción
La privacidad digital vuelve a estar en el centro del debate tras el lanzamiento de Muse Image, el primer modelo generativo de imágenes desarrollado por Meta Superintelligence Labs. Aunque la herramienta promete revolucionar la creación de contenido mediante inteligencia artificial (IA) dentro de WhatsApp e Instagram, su capacidad para utilizar fotos de usuarios como «insumo» sin enviar notificaciones ha generado una fuerte controversia.
¿Qué es Muse Image?
Muse Image es un modelo de generación de imágenes que funciona mediante instrucciones de texto (prompts). Meta ha integrado esta tecnología en su ecosistema, permitiendo que los usuarios de Meta AI generen gráficos de alta precisión sin abandonar el chat. En Instagram, la herramienta potencia funciones creativas en Stories y publicaciones.
Su propuesta es ambiciosa: competir de frente con los generadores de imágenes más avanzados del mercado, ofreciendo un mayor nivel de detalle y coherencia visual.
El conflicto: ¿Privacidad o innovación?
La polémica surge de la capacidad de la IA para procesar perfiles públicos. Mediante comandos simples, un usuario puede solicitar la creación de una imagen que incluya a otra persona, utilizando como referencia las fotografías publicadas en su cuenta de Instagram.
Ejemplos de comandos en disputa:
- «Crea un póster futurista con [usuario]».
- «Convierte a [usuario] en un personaje de fantasía».
El mayor punto de crítica es la ausencia de transparencia: el propietario de las imágenes originales no recibe notificación alguna sobre quién utiliza su contenido, ni cuándo se realiza dicha acción. Actualmente, esta función se limita a cuentas públicas de mayores de 18 años, dejando a los perfiles privados fuera de este alcance.

Pasos para proteger tu privacidad
Expertos en ciberseguridad han señalado que, aunque Meta permite limitar el uso de estas funciones, la opción viene activada por defecto y no es fácilmente accesible. Para proteger tus fotografías, puedes seguir estos pasos:
- Privatiza tu cuenta: La forma más efectiva de evitar que la IA utilice tu contenido es cambiando tu perfil de público a privado en la configuración de Instagram.
- Ajuste manual: Si prefieres mantener tu perfil público, puedes restringir el acceso a tu contenido para funciones de IA:
- Ingresa a la Configuración de tu cuenta de Instagram.
- Busca el apartado «Compartir y reutilizar».
- Desactiva la opción «Permitir que las personas reutilicen tu contenido en Instagram y con las funciones de IA en Meta».
A medida que la inteligencia artificial se integra profundamente en las redes sociales, la gestión de la identidad digital se vuelve una tarea esencial. Se recomienda a los usuarios revisar periódicamente la configuración de sus cuentas para asegurar que sus datos personales no sean utilizados por herramientas generativas sin su consentimiento.

Hallan un cadáver al interior del motel Nueva Castilla, sitio donde fue localizada Debanhi Escobar

Puebla será sede por primera vez del Festival Máster de Voleibol 2026 con más de 700 equipos de todo México

Puebla proyecta la construcción de 50 mil viviendas populares en alianza con el Gobierno Federal






-

 Local23 horas ago
Local23 horas agoVínculos bajo la lupa: SSP investiga encubrimiento local tras el hallazgo de mega-narcolaboratorio
-

 Local16 horas ago
Local16 horas agoPadres exigen cuentas claras por cuotas en primaria «Emiliano Zapata» de Cholula
-

 Local15 horas ago
Local15 horas agoBuscan autobús turístico desaparecido tras viaje de Puebla a Oaxaca
-

 Entretenimiento23 horas ago
Entretenimiento23 horas agoEL MUSEO AMPARO CONVOCA A LA CIUDADANÍA A RECONSTRUIR LA MEMORIA VISUAL DE PUEBLA HASTA 1940
-

 Local24 horas ago
Local24 horas agoGolpe al CJNG: Cae el «M4» y desmantelan célula que controlaba el «huachicol» en Puebla y Tlaxcala
-

 Nacional22 horas ago
Nacional22 horas agoClaudia Sheinbaum alista debate para regular el uso de celulares redes sociales e IA en las escuelas
-

 Local18 horas ago
Local18 horas agoCon inteligencia y estrategia gobierno estatal desmantela la producción de estupefacientes en la Sierra Norte
-

 Policía15 horas ago
Policía15 horas agoAutoridades suspenden áreas quirúrgicas de clínica en San Pedro Cholula tras la muerte de una niña de 6 años